
Meta-Language
The "language" proposed here is a type of real time
state machine or token interpreter which is targeted
at pattern matching and translation using a variation of the BNF grammer.
Other examples are CUMP Byte
Code, and Minimal Controller
Idea.
Examples
| "when you see this" ? "output this" .
| "or change this" ? "into this" .
| @Timer "12:00:00" ? "Good Morning!" @Day = Day + 1 .
| | &h1B ? @PCLState "1" |
| "&f" ? @PCLMacro |
|
| "*p" num | 'X' ... |
| @Comment "This is a comment, it will be copied to the bit bucket" .
to get the current exchange rate with Italy:
@http://www.x-rates.com/htmlgraphs/ITL30.htm 'current rate: ' number ? 'Our
exchange rate with Italy is ' number .
to translate written text to numbers. "one-two" becomes "1-2" The ":" word
causes the OutBuffer to become a local buffer so that the digits that are
matched are placed in a local holding area. When digit is referenced after
the "?" word, the InBuffer is redirected to that local buffer. Each call
to digit adds or removed one entry from the local buffer so that more than
one digit can be matched in a single pattern.
| | 'digit': |
|'zero'?'0'. |
|
|'one'?'1'. |
|
... |
|
|'nine'?'9'. |
|
. |
| digit '-' digit ? digit '-' digit
Word Description
The idea of very small, punctuation type words rather than english keywords
is not commonly seen in programming languages. Years ago, I wondered why
the punctuation marks in standard english text were of no use. The
Bitscope Command Set is a brilliant example of
the application of punctuation to small programming languages. Compair this
to the Oricom
ICTC command set,
NPCI or the
PICos commands.
CUMP Byte Code, and
Minimal Controller
Idea are other attempts. Meta-L tries to use the same meaning of
punctuation symboles from human text in program code. "(" and ")" denote
a comment rather than a memory reference.
| Word |
Description |
|
also
;
|
"Fail to" This word does the following:
-
At compile time:
-
checks and calls OutBuf if necessary to get room for the following
-
places the address (or token) of its run-time code at the OutBuf pointer
and increments the pointer
-
pushes the address of the OutBuf pointer and increments the pointer by a
sufficient amount to reserve space for an address or offset which will eventually
refer to just past the matching period.
-
At run-time
-
Inserts its decision-time address onto the return stack with the address
previously stored after the call to the runtime code
-
Clears the "still-working-on-this-option" flag for the ":" (define) word
-
At return-time aka decision-time (after the following words have executed
and if they return or the "." word has caused a return)
-
If the "success/fail-flag" is set, changes the IP to the address
stored on the stack with the decision-time address.
-
If the "success/fail-flag" is not set, removes the address stored on the
stack with the decision-time address and generates a return.
|
" "
also
&r
|
"Match" The quote form is for standard ASCII text. The & form is
followed by a code indicating radix and is used for binary data e.g. &h1B
or &b00011011 or &o033 are the same value. r can also be a 2 digit
decimal number so &h and &16, &o and &08, &b and &02
are the same. (note that Meta-L is all about conditionals, so the logical
"and" is implied, and "or" is "|" aka Fail to). Match works differently depending
on whether the "?" aka succeed word has appeared. Prior to ?, match rejects
or continues testing the value of an input buffer. After ?, match (and its
"=" form, see below) is copying the result of a match to the output
buffer. The match word does the following :
-
At compile time if succeed ("?") has not appeared yet:
-
checks and calls the current OutBuf method if necessary to get room for the
following (or at least for the run-time code reference, count and a few bytes
of the string)
-
places the address of its run-time code at the OutBuf pointer and increments
the pointer
-
counts the text (up to 254 bytes to make matching an entire buffer easy or
the number of free bytes left in the current Dictionary Chunk) until the
next quote and places that count followed by the text at the OutBufPtr and
points it past the text.
-
if bytes remain, the previous two steps are repeated (allocating Dictionary
Chunks and traversing InBuf Chunks as needed) until all the text is processed.
-
At run-time
-
compares the text at InBufPtr (see "@") to the text following the run-time
address (immediate) and causes a return with CF set if they do not match
-
If there is not enough text at InBufPrt to complete the comparison, calls
InBuf to get (or wait for) more text.
-
At compile time after succeed ("?") has appeared:
-
checks and calls the current OutBuf method if necessary to get room for the
following (or at least for the run-time code reference, count and a few bytes
of the string)
-
places the address (or bytecode) of its run-time code at the OutBufPtr
and increments the pointer
-
counts text (up to 254 bytes or the end of free space in the current OutBuf
Chunk) until the next quote or until the "<" word and places that count
followed by the text at the OutBufPtr and points past the text
-
If the "<" word is found, its compile time code is called to
process the text.
-
if bytes remain, the previous three steps are repeated (traversing OutBuf
and InBuf Chunks as needed) until all the text is processed.
-
At run-time
-
checks and calls the current OutBuf method if necessary to make room then
moves the text following the run-time address to OutBufPtr and calls
OutBuf to dispose of it. This can be done byte at a time in embedded systems.
|
=
|
"Equals" This is a combination of "Match" and "Evaluate" when succeed
("?") has appeared.
-
At compile time
-
checks and calls the current OutBuf method if necessary to get room for the
following (or at least for the run-time code reference, count and a few bytes
of the string)
-
places the address (or bytecode) of its run-time code at the OutBufPtr
and increments the pointer
-
Begins the evaluation of the words in the section using simple
math and variable names defined by the @ word. Constants
are expressed in decimal by default. Other radix are indicated
by different "&" numbers. For example "&o" is octal and "&b"
is binary.
-
At run-time
-
checks and calls the current OutBuf method if necessary to make room then
continues by executing the words following to produce output. It doesn not
affect the "success/fail-flag"
See also: "< >" |
?
|
"Success" or "Then" This word indicates that a match has been made and
sets up the system for output by switching the meaning of the "" word
to the output version vice the input version. At run-time it resets
the "success/fail-flag" so that the "|" (fail-to) word will return rather
than continuing to the next possible match. |
< >
|
"Evaluate" Begins the evaluation of the words in the section using simple
math and variable names defined by the @ word. Constants
are expressed in decimal by default. Other radix are indicated
by different "&" numbers. For example "&o" is octal and "&b"
is binary. See also: "=" |
@
|
"At" changes InBuf (before the ?) or OutBuf (after the ?) to a different
run-time address according to the text following the word and calls
the method code for that word with a "change-time" message. Think of this
as an assembler ORG directive. Actually, @ can just change the outbuffer
to point to the InBuf (before the ?) or OutBuf (after the ?) and the word
following can just OutBuf its address.
Each defined word has a local buffer to hold the result of execution
of that word. These local buffers are accessed by their own words (and
tokens) since the word itself is responsible for setting the pointer
to the local buffer. Words that always generate fresh content when accessed
will point to a zero length buffer (with a method token before the length)
so that their method is always called when InBuf is accessed.
Some pre-defined buffer names may include:
-
For Console IO: @Display, @StdIn, @StdOut
-
Files, by protocol: @file:d:\path\file.ext,
@http://URL/file.ext, @ftp://server/path/file.ext, @telnet
The file buffer method is used to open the file via the local file system,
http get, ftp protocol, etc... and the cache is filled with data.
-
For embedded use: @OutPort , @InPort, @FLASH the address of memory in the
onboard FLASH memory, @PCMCIA the address of memory in the external PCMCIA
FLASH memory.
When calling MetaL from the command line in an OS, the InBuffer will start
as the command line and the OutBuffer will be internal memory. The command
line can change the InBuffer and or OutBuffer to StdIO or what ever as needed.
+n
-n |
Sets InBuf or OutBuf to the buffer name plus an offset. |
|
.
|
"Return" or "Stop" this word returns to the previous level after setting
up the system for input by switching the meaning of the " word to the
input version vice the output version. |
:
|
"Define" causes a new word to be defined in the token dictionary. That
word will store and keep track of what ever its code produces and allow that
product to be recalled and used in other code.
At First:
The following items are placed in the OutBuffer:
-
The define "builds" token
-
the value of a new token which is entered into the Token Table to point
to:
-
a new local thread which calls the Define "Does" buffer handling method followed
by
-
a local buffer, allocated right in the OutBuf. (see
Memory Allocation for Buffers).
-
Tread execution continues in order to compile the rest of the definition
of the defined word into the OutBuf following the local buffer.
"Builds"
The next execution of a given instance of define (when the code before the
":" succeeds) will cause the token created by that define to be placed in
the outbuffer followed by a count of the number of references to this word
in the current code. This count is incremented after each reference and cleared
when "?" (Then) is compiled.
The reference count is also stored on the stack, and a new thread is launched
to finish compiling the code following the reference to this word. After
that thread completes (the "." is executed), the count is restored to its
value at the point where the defined word was referenced.
If the match for the name of the defined word occured after the "?" (Then),
the text following the name of the word is checked for a "#" and a number.
This number, or the current reference count, is placed after the token in
the Outbuffer.
The defined code itself is not executed. The thread started by execution
of the define builds token is stopped (like the "." (stop) word).
"Does"
When the code that uses that definition is executed a new thread will start
with the Define "Does" code (basically a buffer handler method) which behaves
differently if executed before or after "?" (Then).
Before "?" (Then) it will save the OutBufPtr, and make the local Buffer the
OutBuffer,
Each time the word is called, prior to the "?" (Then) word, the reference
count for this instance of the word is checked and the local buffer from
this entry on will be cleared. Data resulting from the execution of the thread
after the original ":" will be appended to the buffer pre-pended with a length
byte.
In any pre "?" (Then) case, DefineDoes will execute the code following the
local Buffer (the code that was compiled when the word was defined). When
that code has completed, the OutBufPtr will be restored and any data OutBuffed
by the code following the define will be available to the calling code by
reference to the defined tokens local buffer.
After the "?" (Then), executing the defined word will simply tranfer the
entry specified by the reference count from the local buffer to the
OutBuf, and return without executing the code for the defined word. |
( )
|
"Comment" Text enclosed in parens are ignored or used to describe the
word when used after a ":" |
|
|
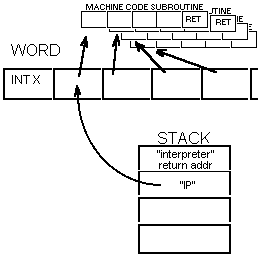 Each word address
is expected to point to a machine language command (i.e. the "interpreter"
just jumps to the code at that address) and that command can be a call (or
more likely a software interrupt or "restart") that invokes the interpreter
with the address of the word on the stack which will point to the addresses
that make up the word.
Each word address
is expected to point to a machine language command (i.e. the "interpreter"
just jumps to the code at that address) and that command can be a call (or
more likely a software interrupt or "restart") that invokes the interpreter
with the address of the word on the stack which will point to the addresses
that make up the word.
Rather than using word addresses, we can use a single byte "token" or index
to a memory address in a table. To increase the number of available subroutines
past 255, some of the routines can implement their own jump table and fetch
the value of a second byte following their own token in the code to use as
an index in their own table. This process can be repeated as often as needed.
To improve performance, the current thread IP can be held in a register (vice
on the stack) and can be pushed to the stack when a new thread is started
by the interpreter.
Instead of a conditional word like MATCH popping its thread to fail to the
next entry, Just set the CY flag and return to FailTo which will then Jump
to the next entry (if CY=1) or return (popping the FailToPtr) to the Parent
(if CY=0) when a simple TRet is encountered indicating success at the end
of a series of trials.
The following example assumes that the inbuffer contains "good"
|
Program |
Stack |
Comment |
| addr0 |
Begin (call interpreter) |
IPInt <addr0> |
|
|
Failto <addr1> |
IPInt <addr0> FailtoRun <addr1> |
|
|
Match "bad" |
IPInt <addr0> FailtoRun <addr1> |
;carry flag set and return |
|
|
IPInt <addr1> |
;FailtoRun Jumps to <addr1> |
| addr1 |
Begin |
IPInt <addr1> |
|
|
Failto <addr2> |
IPInt <addr1> FailtoRun <addr2> |
|
|
Match "good" |
IPInt <addr1> FailtoRun <addr2) |
;Carry flag clear |
|
|
IPInt <addr1> |
;FailtoRun continues at new IP |
|
|
|
|
TRet ;FailtoRun drops <addr> and returns
-
Memory Allocation for Buffers
-
By default, Buffers are initialized as small memory areas (16 bytes) just
after their name entries in the dictionary. The pointer compiled into new
code that references this buffer will point to the length byte following
a pointer to the method used to refill or empty the buffer (see figure 2)
If the length is zero, or insufficient for the required operation, the method
requesting access to the buffer should call the pointer to the buffers method
with a "fill with x bytes" message sent, this will return a pointer to the
filled buffer (not necessarily at the original address) with a new length
indicating the actual number of bytes now in the new buffer. The method is
responsible for interpreting the rest of the data in the buffer. For example:
A dynamic method will take the next byte in the buffer as a chunk pointer
(and see zero,zero as meaning that there is no data and no chunks) but a
virtual pointer will look for a cache len byte or zero followed by a cache
chunk pointer. This system allows binary data to be stored without escapes
via the length byte, but switches to a zero terminated string of pointer
or other data when the length byte is zero. Also, the original pointer to
the buffers length byte should not be confused with a buffer pointer (which
would point not to a length byte but rather to a position in the data of
the buffer).
Memory image of various buffer types
| [(match)<len)(buffername)](bufdef)(token)(startthread)(method |
static)(buffer len:byte=[1...255])(buffer data:15 bytes) |
|
dynamic)(byte=0)(chunk pointer)[(chunk pointer)](byte=0) |
|
virtual)(byte=0)(cache len)(cache:14bytes
max) or (byte=0)(byte=0)(cache chunk pointer)(byte=0) |
|
file)(byte=0)(handle len)(handle/zero if not open)(url len)(url)(offset
len)(file offset)(cache chunk pointer) |
After a static buffer is filled with 15 bytes of data, its method can be
called to "make room" at which time, the static method will be replaced with
a dynamic method and a chunk allocated, the original data moved to it, a
chunk pointer inserted in the buffer, and the length changed to zero. If
the dynamic buffer is not often accessed and free chunks are no longer available,
the chunk allocator may replace the dynamic method with a
virtual method and move the data to a disk
file.
It should be kept in mind that all the program code, data, dictionary etc..
that make up the system must also be contained in buffers. Match, fail, Outbuf
must all take into account the number of bytes left in the current In and
Out buffers and break up output / repeat input operations accordingly. All
programs will basically be paragraph aligned to simplify memory management.
-
Buffers Length

-
Buffers have no maximum length but are processed in 255 byte chunks.
The first byte in a buffer contains its length. As the buffer exceeds 255
bytes an additional index chunk is added that tracks the number of 255 byte
chunks that are contained in the buffer, An invalid byte length value (255,
or zero for easier testing with zero,zero reserved to flag buffers that need
to be refilled) at the start of this new chunk acts as a flag that this index
chunk is present. All the bytes in the index chunk point to other chunks.
When the buffer exceeds 255 chunks of 255 bytes of 64k of data, the next
"meta" index chunk is added indicating one full chunk chunk of data. There
are 256 chunks in a segment.
Note that with this system, it is entirely legal to delete part of
a chunk without having to move the entire file. I.e. we do not have to fill
each chunk completely.
With 14 bytes of data for chunk references, a single small (16 byte)
buffer entry in the dictionary would allow access to 255*14=3570 bytes of
data without calling a method and using only two buffer pointers; one to
the small buffer data to select the chunk pointer and one to select the byte
in the chunk pointed to. By increasing the number of levels of index chunks,
any amount of data can be stored.
To optimize for buffers that are normally accessed sequentially (and
remove the need to store the index chunk in ram which may be critical in
embedded implementations) could buffer data be combined with pointers in
one chunk? e.g. (byte=0)(chunk pointer)(byte=0)(length byte)(data)
| in |
of memory
there are: |
each
containing: |
which can be
selected by
a pointer of: |
| 4GB |
4G bytes |
1 byte |
32 bits |
| 4GB |
16M chunks |
256 bytes |
|
| 4GB |
64k segments |
65536 bytes |
16 bits |
| 1MB |
1M bytes |
1 byte |
20 bits |
| 1MB |
4096 chunks |
256 bytes |
|
| 1MB |
16 segments |
65536 bytes |
4 bits |
| 640KB |
2560 chunks |
256 bytes |
|
| 640KB |
10 segments |
65536 bytes |
4 bits |
| 64KB |
64k bytes |
1 byte |
16 bits |
| 64KB |
256 chunks |
256 bytes |
8 bits |
| 64KB |
2048 buffer entries |
about 32 bytes |
|
|
|
|
|
-
Chunk Pointers
-
To access an unlimited amount of memory without allocating an unlimited
sized address pointer, we can use very small relative pointers that are combined
by having the first pointer point to a second pointer that points etc....
when needed to reference more distant memory.
One problem with this approach is that when an area of memory becomes
completely used, no second pointer may be available within range of the first.
To reduce the risk of this occurring, the meaning of the pointers can be
changed to allow some values to point to distant memory while others point
to local memory with greater granularity. For example, rather than interpret
successive values of a pointer as successive local chunks, cause every other
value to point to a chunk in another segment. Ideally, most values would
still point to local chunks distributed evenly (every other or every 4th
etc..), a smaller number of values would point to chunks less local and still
a smaller number of values would point to chunks still farther away until
finally only a very few values would point to chunks very far away.
The system of value interpretation selected is as follows: shift the
chunk pointer left by the number of bits indicated by the lower 2 bits of
the chunk pointer themselves shifted left one and add to the result the original
lower two bits. This should be easily implemented in most processors with
a register A to register B copy, bit mask register B (and with 0FCh), shift
register A left by register B value, shift register A left by register B
value (again), and an add register B to register A. An
A86 macro has been
developed. The following is an illustration of the chunks that can be referenced
from a chunk pointer relative to any given chuck that contains the pointer
via this interpretation:

-
Each line of pixels represents one segment (256 chunks of 256 bytes or 64k
bytes) and each column represents one chunk with in that segment.
The illustration was generated with a simple
QBASIC program which also prints a
list of address offsets in order generated from
chunk pointer value and sorted by offset value
with distance between offsets. A few chunks almost 16k chunks or 4M bytes
away and about every 4th chunk in the local segment can be referenced. This
is comparable to the x386 index*scale addressing mode.
A second problem with this approach is that each time a new level of
pointers is added, space to store the current value of the pointer must be
allocated. Since all pointers are being mapped to the physical addresses
in the machine (e.g. an index register), we are certainly aware that some
actual upper limit on the address will be reached, however we do not wish
to impose this limit in the structure of the language but only in the actual
implementation on a specific machine.
Chunk Allocation
-
We can specify that some number of chunks be used to hold free/allocated
information in each byte rather than a chunk
pointer. One chunk per segment suffices if each chunks free / allocated
values are limited to 255. Each method that allocates a chunk must select
the related byte in the index and increase its value if it is not already
255. For simplicity, it would seem to be best to combine this system with
a system for tracking frequency of chunk access for virtual memory
management. If we take the value 0 to indicate availability, allocating a
new chunk would consist of:
-
point to the index chunk of the local segment
-
scan for a zero value in a byte related to a chunk that can be pointed to
from the chunk we are adding to, if not found, repeat with each segment that
can be referenced by the chunk we are adding to until no segments are available,
then call the virtual memory manager to dump to secondary memory the least
used chunk from the set to which we can point.
-
change the value of the index byte related to the chunk to be allocated from
zero to one
-
compute and add a chunk pointer to the new chunk
-
Virtual Buffers
-
As buffers grow to large sizes, it may be necessary to move less frequently
used parts (chunks) of the buffer to secondary memory (hard disk). This implies
the following.
-
We must track which chunks are used less frequently
-
We must allocate a file on the disk and track which chunks are stored in
it and where they are in the file
-
When a chunk that is not in memory is needed, some mechanism must retrieve
it from the file.
One solution may be to convert the memory buffer to a file buffer and
then keep track of the chunks that are in cache. We can specify that some
number of chunks be used to hold access count information in each byte rather
than a chunk pointer. One chunk per segment suffices
if each chunks access count is limited to 255. Each method that accesses
a chunk must select the related byte in the index and increase its value
if it is not already 255. It should be noted that we wish to remove first
groups of chunks pointed to by index chunks (because the overhead required
to track the position of the removed chunk is probably greater than the space
that would be released by the removal of one chunk) that A) do not contain
data often needed and B) are not index chunks themselves that are
used to get to data that is often needed. Also, while the relationship between
index chunks that point to infrequently used data is related to the structure
of buffers, it is entirely possible that one part of a buffer will be constantly
in use while another part of the same buffer is never used after its initial
allocation.
For simplicity, it would seem to be best to combine this system with
a system for tracking unused chunks. See Chunk
Allocation elsewhere.
When the virtual memory manager is called to free space:
-
scan through the segment index chunks for each available segment to find
the lowest access count value greater than zero of a chunk index.
-
verify that the chunks pointed to in the selected chunk index are not frequently
used
-
copy all the chunks pointed to by the index chunk to secondary memory, change
their segment index chunk byte value to zero (marking them as free), and
place a reference to the location in the index chunk after a zero length
value and a method token for virtual memory reloading. This assumes that
the code reading the chunks will know to call the method after the
zero byte (rather than before the zero length byte as in a buffer)
when it encounters an index chunk (first byte 255) with no chunk pointers
or a chunk with a zero length.
In the case that only one chunk referenced in a chunk index is repeatedly
called when all the other chunks are never used; if we only increment the
chunk usage count for the index chunk when we shift from one chunk to the
next - since the count will remain low for the index there is a better chance
that it will be selected to page out (good) and if the high usage count for
the high usage chunk is noted when the indexed chunks are being processed,
perhaps the index chunks can be reorganized so that the high usage chunk
is moved to a different index. For example a buffer with only one commonly
used chunk could end up with chunk pointers to index chunks that are all
paged out followed by one chunk pointer directly to the we want to keep handy
followed by more chunk pointer to paged out index chunks. Actually all the
paged out chunks should be combined into one paged out index chunk before
the commonly used chunk and one other after it. This results in only 3 chunks
and the buffer area as the worst case minimum memory usage for any size buffer
where only one chunk is really needed.
-
Buffer list
-
Normally the buffer list would be spread out through memory as new buffers
are created in the dictionary and old buffers are destroyed with matches
and fail-to's used to search the list. But if the buffers list was rearranged
in order by swapping around fail-to pointers so that the last buffer used
was always moved to the first position in the list and if the last position
in the list was quickly accessible (maybe the XOR linked list pointer could
be adapted, this would provide two benefits as the buffer list would sort
itself in the most often used to least often used order over time
-
the chance of finding the buffer you need closer to the top of the list increases
and
-
the buffer at the end of the list is probably the best candidate for swapping
out to virtual memory.
-
-
Persistent Buffers
-
Buffers with a persistent method will be saved to NVM when the system receives
a power off interrupt or constantly in a background process.
-
-
Stack
-
In order to continue the theme of unlimited size, the stack must be implemented
as a buffer which can be upgraded to a virtual method handler. The chunk
allocator should know that chunks buried on the bottom of the stack are less
likely to be needed that chunks near the top.
-
Records / Tables
-
If the name of the buffer contains a '.' dot, the name before the dot is
taken to be a table name and the name after the dot will refer to a field
in that table. Operators to select records by key value, relative or absolute
record number and to add new or delete old records.
-
Arrays / Indexed Tables
-
If the name of a buffer (field or table) ends in a [key], the buffer is taken
to be an indexed array. The key value is used to find an individual element
or record in the buffer and can be any text (Refer to JavaScript arrays)
-
Sequential File System
-
In order to simplify the sequential reading of data that is normally accessed
serially, we can modify the normal index chunk system to also include a
"streaming" linked list where each chunk pointer to
the next chunk of data is stored at the end of the current chunk and is logically
XOR'd with the address of the previous chunk so that the sequence can be
traversed backwards or
forwards.
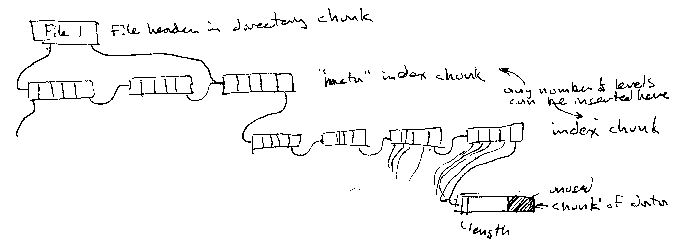
-
Directory Chunk (each memory device must have one at a known starting place)
-
File: array of FileHeader
-
FileHeader
-
file number
starting chunk
ending chunk
length (chunk count and bytes used in last chunk)
-
DataChunk
-
method/file number (for redundancy)?
data
chunk link
-
OpenFile (in ram, like a fcb)
-
file number
chunk pointer
previous chunk pointer
cache
Comparison of variable types
| Name |
Speed |
Structure |
Implemented by |
| register |
super fast |
|
|
| static var |
fast |
direct |
pointer |
| dynamic var |
medium |
indirect |
pointer to pointer |
| virtual |
medium slow |
disk/cache |
VM manager |
| file |
slow |
disk |
bios code |
See also:
See:
file: /Techref/language/meta-l/index.htm, 37KB, , updated: 2016/1/5 16:41, local time: 2025/10/18 14:49,
216.73.216.53,10-2-207-162:LOG IN
|
| | ©2025 These pages are served without commercial sponsorship. (No popup ads, etc...).Bandwidth abuse increases hosting cost forcing sponsorship or shutdown. This server aggressively defends against automated copying for any reason including offline viewing, duplication, etc... Please respect this requirement and DO NOT RIP THIS SITE. Questions?
<A HREF="http://techref.massmind.org/Techref/language/meta-l/index.htm"> Meta-Language</A> |
| Did you find what you needed?
|
| |
Welcome to techref.massmind.org!
|
.
